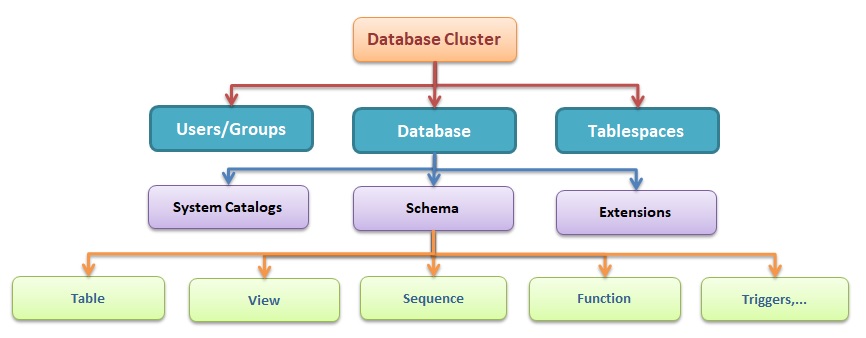
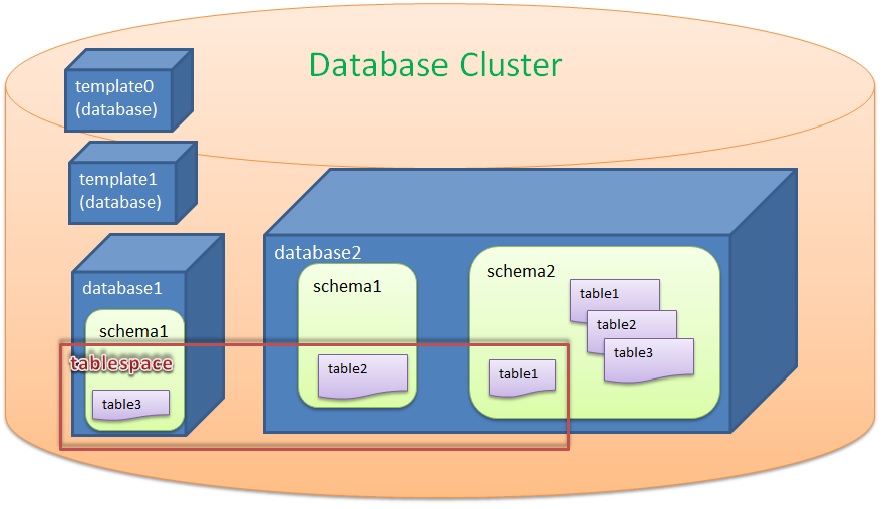
Lời mở đầu
Partitioning bảng dữ liệu, là chức năng tách dữ liệu vật lý của một bảng dữ liệu lớn sang các bảng nhỏ hơn.
Nhờ phân chia dữ liệu được qua các bảng con nhỏ hơn chức năng được biết đến với những lợi ích như bên dưới.
- Tăng performance của hệ thống.
Thay vì truy cập dữ toàn bộ dữ liệu (hay thực hiện scan toàn index), chức năng này chỉ truy cập dữ liệu ở bảng (index) con cần thiết, ngoài ra có thể thực hiện truy vấn song song trên các bảng con nên performance tăng đáng kể nếu có thiết kế thích hợp.
- Quản lý dễ dàng.
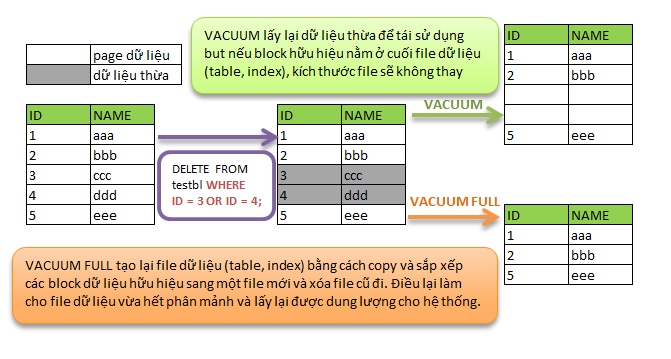
Đối với dữ liệu thiết kế kiểu INSERT/DELETE diễn ra định kỳ. Bạn có thể xoá dữ liệu bằng DROP bảng con không cần thiết, thay vì thực hiện DELETE và VACUUM.
Ngoài ra việc migration dữ liệu, backup/restore, hay các thao tác maintenance dữ liệu như VACUUM/REINDEX cũng diễn ra dễ dàng hơn.
PostgreSQL hỗ trợ chức năng Partitioning bảng dữ liệu.
Trước phiên bản 10, PostgreSQL cung cấp chức năng kế thừa (INHERITS) để thực hiện partitioning bảng dữ liệu. Nhưng việc điều hướng dữ liệu đến các bảng con khi INSERT hay UPDATE không diễn ra tự động mà phải sử dụng TRIGGER để thực hiện.
Bài viết này giới thiệu về chức năng partitioning bảng dữ liệu theo kiến trúc mới, chức năng Declarative Partitioning được đưa vào từ phiên bản PostgreSQL 10.
Scale out cho hệ thống PostgreSQL
Trước khi đi vào giới thiệu cụ thể, xin được tóm tắt các kỹ thuật scale out hệ thống của PostgreSQL hiện tại.
Đối với các hệ thống lớn hay các hệ thống dữ liệu có độ lớn tăng dần theo thời gian, việc thiết kế scale out (chia nhỏ dữ liệu thành nhiều phần để dễ quản lý) là một việc quan trọng nếu không muốn xử lý các vấn đề về dung lượng sau vận hành. PostgeSQL cung cấp các chức năng như bên dưới để hỗ trợ scale out hệ thống.
- Sử dụng TABLESPACE
Từ các phiên bản cũ TABLESPACE đã được sử dụng như công cụ để phân tán dữ liệu qua nhiều đĩa cứng giảm disk I/O. Nhưng gần đây gần đây nhiều hệ thống chuyển qua sử dụng RAID, nên chức năng này cũng không được sử dụng nhiều
- Sử dụng các software liên quan
Sử dụng một số cluster software như PostgreSQL-XL, pacemaker, pgpool-II sử dụng slave node để tham chiếu giảm tải cho master. Hay dùng chức năng load balancer (của pgpool-II),... cũng có thể được coi là một trong các giải pháp scale out. Giải pháp này hơi khó khăn về mặt bảo trì về cấu trúc hệ thống.
- Cascade Replication
Là chức năng đưa vào từ phiên bản 9.2 của PostgreSQL, slave node có thể chuyển tiếp đồng bộ sang các node slave mới.Ta có thể sử dụng chức năng này để scale out cho hệ thống. Hạn chế của cấu trúc này là cascade replication chỉ support phi đồng bộ, thời gian phản ánh WAL (transaction log) lên các slave node có thể trễ, nên dữ liệu trên slave không phải lúc nào cũng là mới nhất.
- Sử dụng postgres_fwd
Contrib postgres_fwd cho phép PostgreSQL kết nối tới server bên ngoài. PostgreSQL 9.6 hỗ trợ push down, kết quả được sử lý (sort, join, ...) ở remote server trước khi gửi về local. Việc này làm giảm tải rất nhiều cho local server trong các hệ thống lớn.
Chức năng này trong tương lai được kỳ vọng là tạo thành nền tảng cho chức năng Sharding giống như các RDBMS như mongodb.
- Partitioning Table
Chức năng phân tán dữ liệu từ một bảng sang nhiều bảng con để tăng khả năng scale out cho hệ thống. Từ Application chỉ cần chú ý tới bảng dữ liệu cha. Dữ liệu khi INSERT/UPDATE vào bảng cha sẽ được phân tán tới các bảng con. Khi SELECT dữ liệu bảng cha, nhờ chức năng Partitioning dữ liệu các bảng con được tập hợp lại và gửi lại cho bảng cha. Các hệ thống cũ thường sử dụng chức năng này kết hợp với TABLESPACE để scale out hệ thống.
Chức năng Partitioning của PostgreSQL
Chức năng này cũng là một chức năng được được PostgreSQL đưa vào sớm từ phiên bản 8.1. Mặc dù có một số hạn chế overhead do phải thiết dựa trên trigger, nhưng chức năng này cũng được sử dụng rộng dãi cho tới nay. Từ phiên bản 10 PostgreSQL hỗ trợ phương thức partitioning mới, không dựa vào trigger nên có performance tốt và cách sử dụng đơn giản.
Chức năng Partitioning sử dụng kế thừa
Ở các phiên bản trước của PostgreSQL 10, để sử dụng chức năng partitioning. Ta cần các bước tổng quan như sau.
- Tạo bảng master
- Tạo các bảng con
- Tạo TRIGGER cho bảng master
Tạo bảng master
Ta tạo bảng master với các trường cần thiết.
Ở đây ta sử dụng cột range cho chức năng partitioning.
10000 postgres@postgres=# CREATE TABLE parent(id integer, childname text, range bigint);
CREATE TABLE
Tạo các bảng con
Bạn có thể định nghĩa số lượng bảng con tuỳ ý theo thiết kế hệ thống của bạn. Nhưng community khuyến cáo không nên sử dụng quá 100 bảng con.
Ví dụ bên dưới mình tạo 3 bảng con kế thừa bảng master.
Ở đây mình sử dụng ràng buộc CHECK dữ liệu, để bảng con tương ứng chỉ chứa những giá trị cho phép.
Khi tham chiếu dữ liệu bảng cha, PostgreSQL có thể dựa vào ràng buộc CHECK của bảng con để bỏ qua tham chiếu tới các bảng con không cần thiết.
10000 postgres@postgres=# CREATE TABLE child1(check(range <= 99999)) inherits(parent);
CREATE TABLE
10000 postgres@postgres=# CREATE TABLE child2(check(range > 99999 and range <= 199999)) inherits(parent);
CREATE TABLE
10000 postgres@postgres=# CREATE TABLE child3(check(range > 199999)) inherits(parent);
CREATE TABLE
10000 postgres@postgres=#
Tạo TRIGGER cho bảng master
Mặc định khi tạo table con ta đã có thể sử dụng chức năng partitioning để truy suất dữ liệu các bảng con thông qua bảng master. Nhưng để insert dữ liệu tới các bảng con thông qua bảng master ta phải sử dụng chức năng TRIGGER của PostgreSQL.
Ví dụ bên dưới thực hiện:
- Tạo hàm TRIGGER insert_to_child cho phép kiểm tra dữ liệu INSERT và, thực hiện INSERT vào các bảng con tương ứng mà không thực hiện INSERT trên bảng master (
return NULL;).
- Sử dụng hàm insert_to_child đã định nghĩa để tạo TRIGGER cho bảng master trước khi INSERT dữ liệu.
Ta có thể sử dụng chức năng RULE của PostgreSQL thay vì tạo TRIGGER. RULE có overhead nhiều hơn TRIGGER khi INSERT 1 hàng, nhưng ngược lại khi INSERT một khối lượng lớn dữ liệu (ví dụ như COPY) thì overhead nhỏ hơn TRIGGER.
10000 postgres@postgres=# CREATE OR REPLACE FUNCTION insert_to_child () RETURNS TRIGGER
AS
$$
BEGIN
IF (NEW.range <= 99999) THEN
INSERT INTO child1 VALUES (NEW.*);
ELSIF (NEW.range > 99999 AND NEW.range <= 199999) THEN
INSERT INTO child2 VALUES (NEW.*);
ELSIF (NEW.range > 199999) THEN
INSERT INTO child3 VALUES (NEW.*);
ELSE
RAISE EXCEPTION 'out of range';
END IF;
RETURN NULL;
END;
$$
LANGUAGE PLPGSQL;
CREATE FUNCTION
10000 postgres@postgres=# CREATE TRIGGER insert_to_child_tg BEFORE INSERT ON parent FOR EACH ROW EXECUTE PROCEDURE insert_to_child();
CREATE TRIGGERSau khi tạo được bảng con và TRIGGER cho bảng master. Bảng master sẽ có cấu trúc như bên dưới.
10000 postgres@postgres=# \d+ parent
Table "public.parent"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-----------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
childname | text | | | | extended | |
range | bigint | | | | plain | |
Triggers:
insert_to_child_tg BEFORE INSERT ON parent FOR EACH ROW EXECUTE PROCEDURE insert_to_child()
Child tables: child1,
child2,
child3Thực hiện truy vấn
INSERT & SELECT dữ liệu
Ví dụ bên dưới INSERT 3 dòng dữ liệu thông qua bảng master và xác nhận dữ liệu đã được ghi vào các bảng con nhờ TRIGGER đã định nghĩa.
10000 postgres@postgres=# INSERT INTO parent VALUES (1,'a',1), (2,'b',199999), (3,'c',200000);
INSERT 0 0
10000 postgres@postgres=# SELECT * FROM parent ;
id | childname | range
----+-----------+--------
1 | a | 1
2 | b | 199999
3 | c | 200000
(3 rows)
10000 postgres@postgres=# SELECT * FROM parent ;
id | childname | range
----+-----------+--------
1 | a | 1
2 | b | 199999
3 | c | 200000
(3 rows)
10000 postgres@postgres=# SELECT * FROM child1;
id | childname | range
----+-----------+-------
1 | a | 1
(1 row)
10000 postgres@postgres=# SELECT * FROM child2;
id | childname | range
----+-----------+--------
2 | b | 199999
(1 row)
10000 postgres@postgres=# SELECT * FROM child3;
id | childname | range
----+-----------+--------
3 | c | 200000
(1 row)
Như kết quả EXPLAIN của câu lệnh SELECT bảng master bên dưới. Dữ liệu được tìm kiếm ở các bảng con chứa dữ liệu tương ứng và bảng master.
10000 postgres@postgres=# EXPLAIN (ANALYZE,VERBOSE) SELECT * FROM parent WHERE range IN (1,199999);
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Append (cost=0.00..48.37 rows=23 width=44) (actual time=0.028..0.039 rows=2 loops=1)
-> Seq Scan on public.parent (cost=0.00..0.00 rows=1 width=44) (actual time=0.011..0.011 rows=0 loops=1)
Output: parent.id, parent.childname, parent.range
Filter: (parent.range = ANY ('{1,199999}'::bigint[]))
-> Seq Scan on public.child1 (cost=0.00..24.12 rows=11 width=44) (actual time=0.015..0.016 rows=1 loops=1)
Output: child1.id, child1.childname, child1.range
Filter: (child1.range = ANY ('{1,199999}'::bigint[]))
-> Seq Scan on public.child2 (cost=0.00..24.12 rows=11 width=44) (actual time=0.008..0.009 rows=1 loops=1)
Output: child2.id, child2.childname, child2.range
Filter: (child2.range = ANY ('{1,199999}'::bigint[]))
Planning Time: 1.433 ms
Execution Time: 0.082 ms
(12 rows)
10000 postgres@postgres=# show constraint_exclusion ;
constraint_exclusion
----------------------
partition
(1 row)PostgreSQL bỏ qua tìm kiếm dữ liệu dựa vào ràng buộc CHECK thông qua tham số constraint_exclusion. Nếu tham số này thiết lập là on hoặc partition, PostgreSQL sẽ sử dụng ràng buộc CHECK để bỏ qua tìm kiếm ở bảng con không cần thiết.
Ví dụ bên dưới khi set constraint_exclusion sang off, PostgreSQL scan tất cả các bảng con.
10000 postgres@postgres=# set constraint_exclusion TO off;
SET
10000 postgres@postgres=# EXPLAIN (ANALYZE,VERBOSE) SELECT * FROM parent WHERE range IN (1,199999);
QUERY PLAN
----------------------------------------------------------------------------------------------------------------
Append (cost=0.00..72.55 rows=34 width=44) (actual time=0.021..0.053 rows=2 loops=1)
-> Seq Scan on public.parent (cost=0.00..0.00 rows=1 width=44) (actual time=0.006..0.006 rows=0 loops=1)
Output: parent.id, parent.childname, parent.range
Filter: (parent.range = ANY ('{1,199999}'::bigint[]))
-> Seq Scan on public.child1 (cost=0.00..24.12 rows=11 width=44) (actual time=0.013..0.014 rows=1 loops=1)
Output: child1.id, child1.childname, child1.range
Filter: (child1.range = ANY ('{1,199999}'::bigint[]))
-> Seq Scan on public.child2 (cost=0.00..24.12 rows=11 width=44) (actual time=0.007..0.007 rows=1 loops=1)
Output: child2.id, child2.childname, child2.range
Filter: (child2.range = ANY ('{1,199999}'::bigint[]))
-> Seq Scan on public.child3 (cost=0.00..24.12 rows=11 width=44) (actual time=0.022..0.022 rows=0 loops=1)
Output: child3.id, child3.childname, child3.range
Filter: (child3.range = ANY ('{1,199999}'::bigint[]))
Rows Removed by Filter: 1
Planning Time: 0.299 ms
Execution Time: 0.128 ms
(16 rows)UPDATE dữ liệu
Như ví dụ bên dưới vì ta chưa tạo TRIGGER khi UPDATE bảng master. Nên dữ liệu UPDATE không nằm trong khoảng của ràng buộc CHECK sẽ gây ra lỗi. Nếu muốn khắc phục lỗi này ta phải định nghĩa thêm TRIGGER thực hiện điều hướng dữ liệu UPDATE tới các bảng con tương ứng.
10000 postgres@postgres=# UPDATE parent SET range = 200000 WHERE range = 1;
ERROR: new row for relation "child1" violates check constraint "child1_range_check"
DETAIL: Failing row contains (1, a, 200000).
10000 postgres@postgres=# UPDATE parent SET range = 2 WHERE range = 1;
UPDATE 1
10000 postgres@postgres=#
Declarative Partitioning (PostgreSQL 10 ~)
Nếu như ta phải thực hiện nhiều thao tác mới sử dụng được chức năng Partitioning sử dụng kế thừa như trên, thì từ phiên bản 10 ta chỉ đơn giản thực hiện các thao tác bên dưới là có thể sử dụng được.
- Tạo bảng master với tuỳ chọn partitioning
- Tạo bảng con tương ứng cho bảng master
Tạo bảng master Declarative Partitioning
Chức năng Declarative Partitioning hỗ trợ các phương thức partitioning như sau:
- range (PostgreSQL 10~) Chỉ định phạm vi giá trị cho cột khoá của mỗi bảng con
- list (PostgreSQL 10~) Chỉ định danh sách giá trị cho cột khoá của mỗi bảng con
- hash (PostgreSQL 11~)
Sử dụng hash để chỉ định giá trị cho cột khoá của mỗi bảng con
Ví dụ bên dưới mình sử dụng phương thức range (tương ứng với ví dụ ở chức năng partitioning sử dụng kế thừa).
10000 postgres@postgres=# CREATE TABLE parent_pg10(id integer, name text, range bigint) PARTITION BY RANGE (range);
CREATE TABLE
Tạo bảng con tương ứng cho bảng master
10000 postgres@postgres=# CREATE TABLE child1_pg10 PARTITION OF parent_pg10 FOR VALUES FROM (0) TO (99999) ;
CREATE TABLE
10000 postgres@postgres=# CREATE TABLE child2_pg10 PARTITION OF parent_pg10 FOR VALUES FROM (99999) TO (200000) ;
CREATE TABLE
10000 postgres@postgres=# CREATE TABLE child3_pg10 PARTITION OF parent_pg10 FOR VALUES FROM (200000) TO (9223372036854775807) ;
CREATE TABLE
Sau khi tạo được bảng con. Bảng master sẽ có cấu trúc như bên dưới.
10000 postgres@postgres=# \d+ parent_pg10
Table "public.parent_pg10"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
name | text | | | | extended | |
range | bigint | | | | plain | |
Partition key: RANGE (range)
Partitions: child1_pg10 FOR VALUES FROM ('0') TO ('99999'),
child2_pg10 FOR VALUES FROM ('99999') TO ('200000'),
child3_pg10 FOR VALUES FROM ('200000') TO ('9223372036854775807')Thực hiện truy vấn
INSERT & SELECT dữ liệu
Ví dụ bên dưới INSERT 3 dòng dữ liệu thông qua bảng master và xác nhận dữ liệu đã được ghi vào các bảng con nhờ chức năng Declarative Partitioning.
10000 postgres@postgres=# INSERT INTO parent_pg10 VALUES (1,'a',1), (2,'b',199999), (3,'c',200000);
INSERT 0 3
10000 postgres@postgres=# SELECT * FROM parent_pg10 ;
id | name | range
----+------+--------
1 | a | 1
2 | b | 199999
3 | c | 200000
(3 rows)
10000 postgres@postgres=# SELECT * FROM child1_pg10 ;
id | name | range
----+------+-------
1 | a | 1
(1 row)
10000 postgres@postgres=# SELECT * FROM child2_pg10 ;
id | name | range
----+------+--------
2 | b | 199999
(1 row)
10000 postgres@postgres=# SELECT * FROM child3_pg10 ;
id | name | range
----+------+--------
3 | c | 200000
(1 row)
Như kết quả EXPLAIN của câu lệnh SELECT bảng master bên dưới. Mặc định dữ liệu được tìm kiếm qua các bảng con chứa dữ liệu tương ứng (bảng master không chứa dữ liệu).
10000 postgres@postgres=# EXPLAIN (ANALYZE,VERBOSE) SELECT * FROM parent_pg10 WHERE range IN (1,199999);
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Append (cost=0.00..48.36 rows=22 width=44) (actual time=0.028..0.041 rows=2 loops=1)
-> Seq Scan on public.child1_pg10 (cost=0.00..24.12 rows=11 width=44) (actual time=0.027..0.028 rows=1 loops=1)
Output: child1_pg10.id, child1_pg10.name, child1_pg10.range
Filter: (child1_pg10.range = ANY ('{1,199999}'::bigint[]))
-> Seq Scan on public.child2_pg10 (cost=0.00..24.12 rows=11 width=44) (actual time=0.010..0.010 rows=1 loops=1)
Output: child2_pg10.id, child2_pg10.name, child2_pg10.range
Filter: (child2_pg10.range = ANY ('{1,199999}'::bigint[]))
Planning Time: 1.352 ms
Execution Time: 0.099 ms
(9 rows)Cũng giống với chức năng partitioning sử dụng kết thừa. Sau khi set tham số constraint_exclusion sang off, dữ liệu được tìm kiếm trên tất cả các bảng.
Ở phiên bản PostgreSQL 11, PostgreSQL không sử dụng exclusion constraint cho việc loại trừ tìm kiếm dữ liệu bảng con không cần thiết (prunning), nên tham số constraint_exclusion không có hiệu lực, thay vào đó ta sử dụng tham số enable_partition_pruning.
10000 postgres@postgres=# set constraint_exclusion to off;
SET
10000 postgres@postgres=# set constraint_EXPLAIN (ANALYZE,VERBOSE) SELECT * FROM parent_pg10 WHERE range IN (1,199999);
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Append (cost=0.00..26.15 rows=13 width=44) (actual time=0.017..0.046 rows=2 loops=1)
-> Seq Scan on public.child1_pg10 (cost=0.00..1.01 rows=1 width=44) (actual time=0.016..0.017 rows=1 loops=1)
Output: child1_pg10.id, child1_pg10.name, child1_pg10.range
Filter: (child1_pg10.range = ANY ('{1,199999}'::bigint[]))
-> Seq Scan on public.child2_pg10 (cost=0.00..1.01 rows=1 width=44) (actual time=0.007..0.007 rows=1 loops=1)
Output: child2_pg10.id, child2_pg10.name, child2_pg10.range
Filter: (child2_pg10.range = ANY ('{1,199999}'::bigint[]))
-> Seq Scan on public.child3_pg10 (cost=0.00..24.12 rows=11 width=44) (actual time=0.020..0.020 rows=0 loops=1)
Output: child3_pg10.id, child3_pg10.name, child3_pg10.range
Filter: (child3_pg10.range = ANY ('{1,199999}'::bigint[]))
Rows Removed by Filter: 1
Planning time: 0.278 ms
Execution time: 0.090 ms
(13 rows)UPDATE dữ liệu
- Ở phiên bản PostgreSQL 10, cũng giống như với partitioning sử dụng kế thừa, câu lệnh UPDATE thất bại nếu dữ liệu mới cho cột key nằm ở partition khác.
10000 postgres@postgres=# UPDATE parent_pg10 SET range = 200001 WHERE range = 1;
ERROR: new row for relation "child1_pg10" violates partition constraint
DETAIL: Failing row contains (1, a, 200001).
- Ở phiên bản PostgreSQL 11, hạn chế bên trên đã được loại bỏ, dữ liệu tự động điều hướng sang partition tương ứng.
11000 postgres@postgres=# UPDATE parent_pg10 SET range = 200001 WHERE range = 1;
UPDATE 1
11000 postgres@postgres=# SELECT * FROM child3_pg10 ;
id | name | range
----+------+--------
3 | c | 200000
1 | a | 200001
(2 rows)
Ở trường hợp dữ liệu đồng thời được update trên một cột key, có thể xảy ra lỗi, vui lòng xem mục hạn chế ở cuối bài viết này.
Performance
Như ví dụ bên dưới. Do có overhead bởi TRIGGER, Performance của INSERT giảm rõ rệt (~10 lần) khi sử dụng phương thức partitioning sử dụng kế thừa.
- Kết quả EXPLAIN sử dụng phương thức partitioning sử dụng kế thừa.
10000 postgres@postgres=# EXPLAIN (ANALYZE,VERBOSE) INSERT INTO parent SELECT generate_series(1,999999),'CHILD', random()*10000000;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Insert on public.parent (cost=0.00..17.52 rows=1000 width=44) (actual time=33340.724..33340.724 rows=0 loops=1)
-> Subquery Scan on "*SELECT*" (cost=0.00..17.52 rows=1000 width=44) (actual time=0.008..1278.986 rows=999999 loops=1)
Output: "*SELECT*".generate_series, 'CHILD'::text, "*SELECT*"."?column?_1"
-> ProjectSet (cost=0.00..5.02 rows=1000 width=44) (actual time=0.005..692.425 rows=999999 loops=1)
Output: generate_series(1, 999999), NULL::unknown, (random() * '10000000'::double precision)
-> Result (cost=0.00..0.01 rows=1 width=0) (actual time=0.001..0.001 rows=1 loops=1)
Planning Time: 0.076 ms
Trigger insert_to_child_tg: time=31178.106 calls=999999
Execution Time: 33340.757 ms
(9 rows)- Kết quả EXPLAIN sử dụng phương thức Declarative Partitioning.
10000 postgres@postgres=# EXPLAIN (ANALYZE,VERBOSE) INSERT INTO parent_pg10 SELECT generate_series(1,999999),'CHILD', random()*10000000;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Insert on public.parent_pg10 (cost=0.00..17.52 rows=1000 width=44) (actual time=3814.105..3814.105 rows=0 loops=1)
-> Subquery Scan on "*SELECT*" (cost=0.00..17.52 rows=1000 width=44) (actual time=0.011..646.356 rows=999999 loops=1)
Output: "*SELECT*".generate_series, 'CHILD'::text, "*SELECT*"."?column?_1"
-> ProjectSet (cost=0.00..5.02 rows=1000 width=44) (actual time=0.007..328.986 rows=999999 loops=1)
Output: generate_series(1, 999999), NULL::unknown, (random() * '10000000'::double precision)
-> Result (cost=0.00..0.01 rows=1 width=0) (actual time=0.001..0.002 rows=1 loops=1)
Planning Time: 0.100 ms
Execution Time: 3814.203 ms
(8 rows)Một số hạn chế và chú ý liên quan tới chức năng Declarative Partitioning
- Không hỗ trợ Primary Key cho cột khoá
10000 postgres@postgres=# alter table child1_pg10 add primary key (range);
ERROR: multiple primary keys for table "child1_pg10" are not allowed
- Không hỗ trợ khoá ngoại lai
Không hỗ hợ Primary Key đồng nghĩa với không hỗ trợ khoá ngoại lai tham chiếu tới cột khoá.
10000 postgres@postgres=# create table grand_child(id integer, name text, range bigint references child1(range));
ERROR: there is no unique constraint matching given keys for referenced table "child1"
- Cập nhật dữ liệu sang partition khác (hạn chế ở phiên bản
PostgreSQL 10, đã được fixed ở phiên bản 11)
- Ở phiên bản PostgreSQL 10, Declarative Partitioning không hỗ trợ lệnh UPDATE chuyển dữ liệu từ partition này qua partition khác.
10000 postgres@postgres=# UPDATE parent_pg10 SET range = 200001 WHERE range = 1;
ERROR: new row for relation "child1_pg10" violates partition constraint
DETAIL: Failing row contains (1, a, 200001).
- Phiên bản PostgreSQL 11 đã loại bỏ được hạn chế bên trên, nhưng nếu dữ liệu đang được chuyển qua partition khác, cùng lúc đó có lệnh UPDATE đối với dữ liệu tương ứng sẽ có thể xảy ra lỗi như bên dưới.
11000 postgres@postgres=#* update parent_pg10 SET range = 1000;
ERROR: tuple to be updated was already moved to another partition due to concurrent update
- Không hỗ trợ ON CONFLICT (hạn chế ở phiên bản
PostgreSQL 10, đã được fixed ở phiên bản 11)
- Ở phiên bản 10 Declarative Partitioning không hỗ trợ cấu trúc ON CONFLICT.
10000 postgres@postgres=# insert into parent_pg10 values(1,'a',1) on conflict do nothing;
ERROR: ON CONFLICT clause is not supported with partitioned tables
- Hạn chế này đã được fixed tại phiên bản 11.
11000 postgres@postgres=#* into parent_pg10 values(1,'a',1) on conflict do nothing;
INSERT 0 0
-
TRIGGER mức độ dòng dữ liệu phải được định nghĩa ở bảng con, vì bảng cha không chứa dữ liệu.
-
Bảng con của một bảng master không thể có cả bảng cố định và bảng tạm thời (temp table).
11000 postgres@postgres=# CREATE temp TABLE child3_pg11 PARTITION OF parent_pg10 FOR VALUES FROM (200000) TO (9223372036854775807) ;
ERROR: cannot create a temporary relation as partition of permanent relation "parent_pg10"
- Không hỗ trợ full cho postgres_fdw (hạn chế ở phiên bản
PostgreSQL 10, đã được fixed ở phiên bản 11).
Ta có thể sử dụng chức năng partitioning table kết hợp với postgres_fdw để scale out hệ thống như bên dưới ở phiên bản PostgreSQL 11.
Ở phiên bản 10 có thể cấu hình được hệ thống bên dưới, nhưng hệ thống chưa hỗ trợ hoàn toàn các câu lệnh SQL cho postgres_fdw.
Hệ thống ví dụ bên dưới, sử dụng chức năng partitioning với 2 bảng con, 2 bảng con này tiếp tục được đồng bộ sang các DB install khác thông qua chức năng postgres_fdw.
===========================================
DB install 1: Bảng master
|
+- partitioning -+
| |
bảng con 1 bảng con 2
| |
===================+==postgres_fdw==+======
DB install 2: | |
bảng con 1 |
| |
===================+==postgres_fdw==+======
DB install 3: |
bảng con 2
|
===========================================
Những thay đổi ở phiên bản PostgreSQL 11
Ở phiên bản PostgreSQL 11, có 3 cải thiện chính như bên dưới.
Faster partition pruning
Ở phiên bản 10 PostgreSQL sử dụng constraint_exclusion để bỏ qua partition không cần thiết. Việc loại bỏ này thực hiện bởi sử dụng giá trị ở WHERE clause rồi so sánh với các metadata của từng partition. Phiên bản 11 không sử dụng constraint_exclusion nữa mà thực hiện tìm kiếm trực tiếp tới partition cần thiết làm tăng performance.
Partition Pruning at Execution Time
Phiên bản 10 thực hiện bỏ qua partition không cần thiết (prunning) ở giai đoạn planning. Nếu chỉ thực hiện ở giai đoạn này, PostgreSQL sẽ không thể thực hiện prunning được những câu lệnh có truy vấn phụ như ví dụ bên dưới.
- Ở phiên bản 10, PostgreSQL thực hiện scan trên tất cả các bảng con khi biểu thức tìm kiếm là một truy vấn phụ vì truy vấn chưa được thực thi ở giai đoạn planning.
10000 postgres@postgres=# explain (analyze, verbose) select * from parent_pg10 where range = (select id from temp);
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Append (cost=35.50..19111.50 rows=3 width=18) (actual time=210.733..210.733 rows=0 loops=1)
InitPlan 1 (returns $0)
-> Seq Scan on public.temp (cost=0.00..35.50 rows=2550 width=4) (actual time=0.006..0.007 rows=1 loops=1)
Output: temp.id
-> Seq Scan on public.child1_pg10 (cost=0.00..192.64 rows=1 width=18) (actual time=3.033..3.033 rows=0 loops=1)
Output: child1_pg10.id, child1_pg10.name, child1_pg10.range
Filter: (child1_pg10.range = $0)
Rows Removed by Filter: 10051
-> Seq Scan on public.child2_pg10 (cost=0.00..192.30 rows=1 width=18) (actual time=2.420..2.420 rows=0 loops=1)
Output: child2_pg10.id, child2_pg10.name, child2_pg10.range
Filter: (child2_pg10.range = $0)
Rows Removed by Filter: 10024
-> Seq Scan on public.child3_pg10 (cost=0.00..18691.06 rows=1 width=18) (actual time=205.277..205.277 rows=0 loops=1)
Output: child3_pg10.id, child3_pg10.name, child3_pg10.range
Filter: (child3_pg10.range = $0)
Rows Removed by Filter: 979925
Planning time: 0.287 ms
Execution time: 210.785 ms
(18 rows)- PostgreSQL 11 thực hiện prunning khi thực thi truy vấn. Nên có thể đối ứng cả truy vấn phụ.
11000 postgres@postgres=# explain (analyze, verbose) select * from parent_pg10 where range = (select id from temp);
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Append (cost=35.50..18906.51 rows=3 width=18) (actual time=6.997..6.997 rows=0 loops=1)
InitPlan 1 (returns $0)
-> Seq Scan on public.temp (cost=0.00..35.50 rows=2550 width=4) (actual time=0.799..0.801 rows=1 loops=1)
Output: temp.id
-> Seq Scan on public.child1_pg10 (cost=0.00..190.64 rows=1 width=18) (actual time=6.157..6.157 rows=0 loops=1)
Output: child1_pg10.id, child1_pg10.name, child1_pg10.range
Filter: (child1_pg10.range = $0)
Rows Removed by Filter: 10051
-> Seq Scan on public.child2_pg10 (cost=0.00..189.30 rows=1 width=18) (never executed)
Output: child2_pg10.id, child2_pg10.name, child2_pg10.range
Filter: (child2_pg10.range = $0)
-> Seq Scan on public.child3_pg10 (cost=0.00..18491.06 rows=1 width=18) (never executed)
Output: child3_pg10.id, child3_pg10.name, child3_pg10.range
Filter: (child3_pg10.range = $0)
Planning Time: 0.377 ms
Execution Time: 7.052 ms
(16 rows)
Như đã nói ở trên. Do PostgreSQL 10 không sử dụng exclusion constraint để bỏ qua partition không cần thiết, nên tham số constraint_exclusion không có hiệu lực đối với Declarative Partitioning trên phiên bản 11, thay vào đó là parameter enable_partition_pruning (mặc định là on).
Hỗ trợ hash partitioning
Ngoài kiểu range và list ở PostgreSQL 10, PostgreSQL 11 hỗ trợ thêm partitioning kiểu hash.
Thông qua hàm hash của PostgreSQL, dữ liệu INSERT vào cột khoá (cột partitioning) sẽ được điều hướng tới bảng con tương ứng.
Ví dụ:
11000 postgres@postgres=# create table parent_hash(id name, child text, hashval text) partition by hash (hashval);
CREATE TABLE
- Tạo bảng con
Modulus có thể hiểu là số lượng partition cho bảng master. Remainder là số dư khi chia hash của giá trị INSERT vào cho số Modulus tương ứng.
11000 postgres@postgres=# create table child1_hash partition of parent_hash for values with (modulus 3, remainder 0);
CREATE TABLE
11000 postgres@postgres=# create table child2_hash partition of parent_hash for values with (modulus 3, remainder 1);
CREATE TABLE
11000 postgres@postgres=# create table child3_hash partition of parent_hash for values with (modulus 3, remainder 2);
CREATE TABLE
11000 postgres@postgres=# explain (analyze, verbose) insert into parent_hash select generate_series(1,10000000),'child',random()::text;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Insert on public.parent_hash (cost=0.00..20.02 rows=1000 width=128) (actual time=66464.827..66464.827 rows=0 loops=1)
-> Subquery Scan on "*SELECT*" (cost=0.00..20.02 rows=1000 width=128) (actual time=0.024..23043.207 rows=10000000 loops=1)
Output: "*SELECT*".generate_series, 'child'::text, "*SELECT*".random
-> ProjectSet (cost=0.00..5.03 rows=1000 width=68) (actual time=0.018..16336.944 rows=10000000 loops=1)
Output: generate_series(1, 10000000), NULL::unknown, (random())::text
-> Result (cost=0.00..0.01 rows=1 width=0) (actual time=0.002..0.002 rows=1 loops=1)
Planning Time: 0.091 ms
Execution Time: 66466.265 ms
(8 rows)
11000 postgres@postgres=# \d+ parent_hash
Table "public.parent_hash"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
---------+------+-----------+----------+---------+----------+--------------+-------------
id | name | | | | plain | |
child | text | | | | extended | |
hashval | text | | | | extended | |
Partition key: HASH (hashval)
Partitions: child1_hash FOR VALUES WITH (modulus 3, remainder 0),
child2_hash FOR VALUES WITH (modulus 3, remainder 1),
child3_hash FOR VALUES WITH (modulus 3, remainder 2)
11000 postgres@postgres=# select count(*) from child1_hash;
count
---------
3332642
(1 row)
11000 postgres@postgres=# select count(*) from child2_hash;
count
---------
3333466
(1 row)
11000 postgres@postgres=# select count(*) from child3_hash;
count
---------
3333892
(1 row)
11000 postgres@postgres=# select count(*) from only parent_hash;
count
-------
0
(1 row)
-- Dữ liệu được tìm kiếm ở bảng tương ứng (public.child1_hash)
11000 postgres@postgres=# explain (analyze, verbose) select * from parent_hash where hashval = '0.413760441355407';
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..74228.30 rows=1 width=88) (actual time=1.003..522.970 rows=1 loops=1)
Output: child1_hash.id, child1_hash.child, child1_hash.hashval
Workers Planned: 2
Workers Launched: 2
-> Parallel Append (cost=0.00..73228.20 rows=1 width=88) (actual time=342.915..516.902 rows=0 loops=3)
Worker 0: actual time=514.096..514.096 rows=0 loops=1
Worker 1: actual time=514.136..514.136 rows=0 loops=1
-> Parallel Seq Scan on public.child1_hash (cost=0.00..73228.19 rows=1 width=88) (actual time=342.908..516.894 rows=0 loops=3)
Output: child1_hash.id, child1_hash.child, child1_hash.hashval
Filter: (child1_hash.hashval = '0.413760441355407'::text)
Rows Removed by Filter: 1110880
Worker 0: actual time=514.088..514.088 rows=0 loops=1
Worker 1: actual time=514.127..514.127 rows=0 loops=1
Planning Time: 1.810 ms
Execution Time: 526.021 ms
(15 rows)
--chưa hỗ trợ LIKE clause (dữ liệu không được prunning)
11000 postgres@postgres=# explain (analyze, verbose) select * from parent_hash where hashval like '%41376044135%';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..220838.95 rows=1002 width=88) (actual time=2.684..1956.412 rows=1 loops=1)
Output: child2_hash.id, child2_hash.child, child2_hash.hashval
Workers Planned: 2
Workers Launched: 2
-> Parallel Append (cost=0.00..219738.75 rows=417 width=88) (actual time=1298.137..1949.377 rows=0 loops=3)
Worker 0: actual time=1945.537..1945.537 rows=0 loops=1
Worker 1: actual time=1946.631..1946.631 rows=0 loops=1
-> Parallel Seq Scan on public.child2_hash (cost=0.00..73259.59 rows=139 width=88) (actual time=655.334..655.334 rows=0 loops=3)
Output: child2_hash.id, child2_hash.child, child2_hash.hashval
Filter: (child2_hash.hashval ~~ '%41376044135%'::text)
Rows Removed by Filter: 1111155
Worker 0: actual time=9.694..9.694 rows=0 loops=1
Worker 1: actual time=1946.623..1946.623 rows=0 loops=1
-> Parallel Seq Scan on public.child3_hash (cost=0.00..73248.88 rows=139 width=88) (actual time=968.696..968.696 rows=0 loops=2)
Output: child3_hash.id, child3_hash.child, child3_hash.hashval
Filter: (child3_hash.hashval ~~ '%41376044135%'::text)
Rows Removed by Filter: 1666946
Worker 0: actual time=1935.832..1935.832 rows=0 loops=1
-> Parallel Seq Scan on public.child1_hash (cost=0.00..73228.19 rows=139 width=88) (actual time=2.242..1944.713 rows=1 loops=1)
Output: child1_hash.id, child1_hash.child, child1_hash.hashval
Filter: (child1_hash.hashval ~~ '%41376044135%'::text)
Rows Removed by Filter: 3332641
Planning Time: 0.471 ms
Execution Time: 1961.897 ms
(24 rows)Kết luận
Cùng với chức năng logical replication, chức năng Declarative Partitioning được đưa vào từ phiên bản PostgreSQL 10 được coi là một bước tiến đáng kể của PostgreSQL.
Chức năng Declarative Partitioning kết hợp với postgres_fdw có thể là nền tảng cho chức năng sharding của PostgreSQL sau này.
Phiên bản 11 khắc phục khá lớn các hạn chế của Declarative Partitioning trong phiên bản 10. Mặc dù vậy cũng cần chú ý các hạn chế còn tồn đọng để thiết kết xử lý sao cho đúng với hệ thống của bạn.